【高可用】高可用架构设计 学习笔记(长文,但觉得并不实用)
属于感性理解还可以,并不适合上手。 讲得方方面面很多,但都不深入。也不能实操。
高可用架构设计
第一课:什么是高可用
如何评价高可用?断开服务时间和运行时间的比例 99% = 88小时 /一年 99.9% = 8小时/一年 99.99% = 8分钟/一年
第二课:高可用架构分层:
2.1 不是越多越好
- 前台: MVC
- 后台:
- 按功能分4~5层:接入层、(异步消息队列序列化层)、逻辑层、数据层、存储层
- 按业务垂直拆分:
- 房产,招聘
- IM,交友
- 分的少:耦合
- 分的多:维护成本高,延迟,定位问题复杂度增加,定位时间增加
2.2 为什么需要分层?
耦合,扩展性不强,增加了down的几率。
<font color=red>
- 传统开发spring或struts分开开发mvc是然后做一个war或jar,这叫逻辑分层。(发布上)(进程上)
- 而这里说的分层,指的是物理分层,就像微服务。每层上有多个服务。层之间靠api来通信。
- 服务的切分。
</font>
2.3 到底分几层?怎么去分层
A: 必须看业务场景。不看业务场景谈架构是没有意义的。来源于业务场景服务于业务场景。
-
- 创业初期 - 让公司先活下来再说
- 满足业务快速发展
- 可用性低也行
- 分层少 OK。不分也OK
- ALL in one (MVC)完全OK
- 创业初期 - 让公司先活下来再说
-
- 请求量和数据量在快速爆发时期
- 引入分层
- 接入层、逻辑层、数据层
- 满足业务增长需求
- 请求量和数据量在快速爆发时期
-
- 业务高并发、海量存储
- 每层进一步细化
- 分布式存储、NoSql、RDBMS分库分表
- 业务高并发、海量存储
-
- 业务多、请求多、关系复杂
- 58列表页 、详情页问题
- 服务化(API接口来互相衔接,而不是jar包互相依赖)
- 解耦、稳定
- 业务多、请求多、关系复杂
2.4 分层的真实最佳实践案例
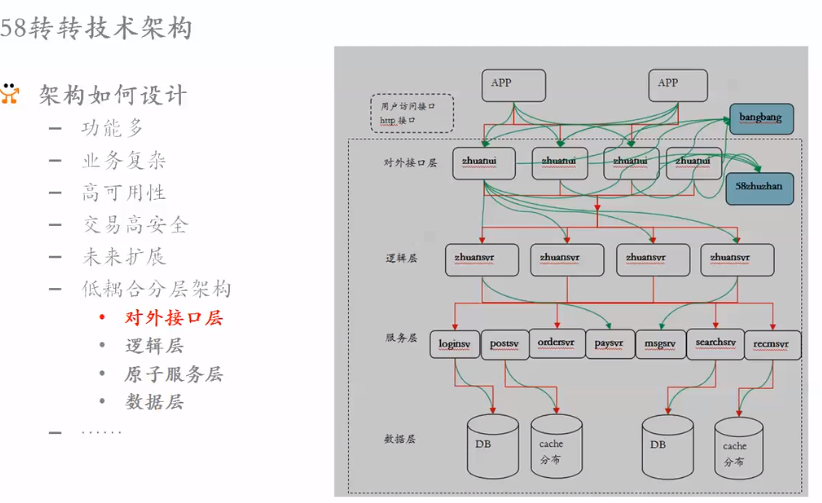
2.4.1 案例1:58帮帮
定位:传统IM,满足58用户和商户沟通。就像淘宝旺旺。
性能:千万用户同时在线。
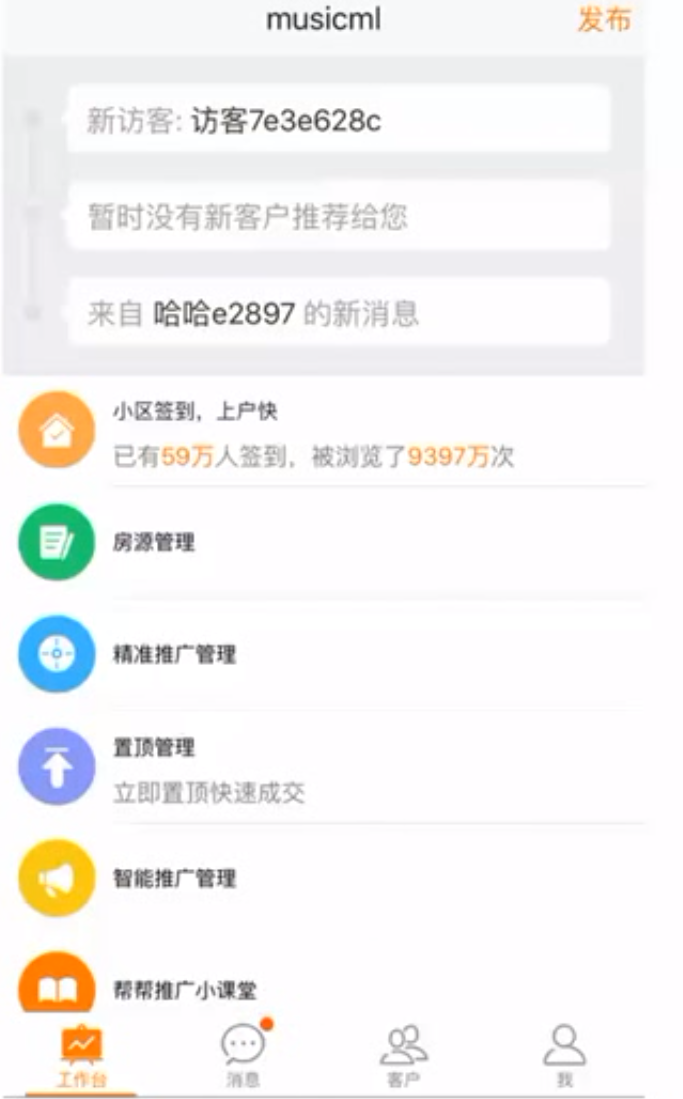 架构:
架构:
- 接入层:
- 长连接加密(TCP),
- web上js-http长连接。
- 用户连接后没有操作,后台就断掉连接:攻防。
- 用户身份校验(用户名)
- 转发逻辑层
- 逻辑层:
- 黑名单加入了没有,加入了就忽略消息
- antispam系统
- 路由层:
- 在线的状态信息。隐身、离开等与session相关信息。没必要保留在数据库中,而是缓存在RS层。
- 记录了每个用户接入层的节点。
- 发消息是,在路由层找到该用户的接入层,就找到该用户用的长连接。就发消息过去了。
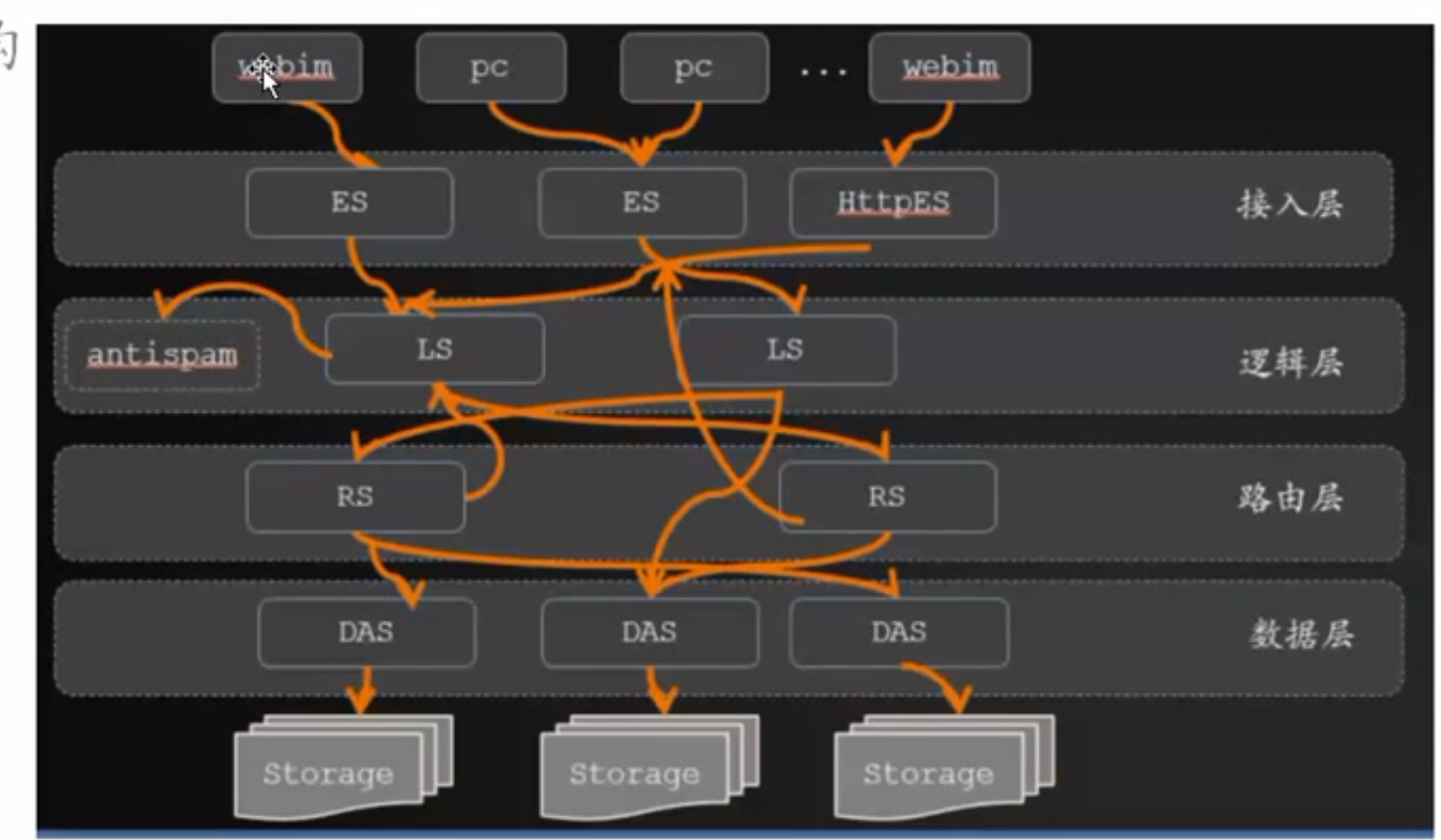
2.4.2 案例2: 服务器推送消息文本、图片、音频、视频
移动互联网的最基础需求,因为移动互联网的网络是不稳定的,所以需要异步推送消息。保证通知到。 定位:58同一的移动push推送平台 吞吐量:10W+QPS 推送两:每天10亿+ 很多App接入该平台。
- 接入层:
- push entry 消息队列入口
- push transfer: 校验(token)和转发
- 出口层
- android出口
- ios 出口
- 第三方推送平台:
- 苹果:apns
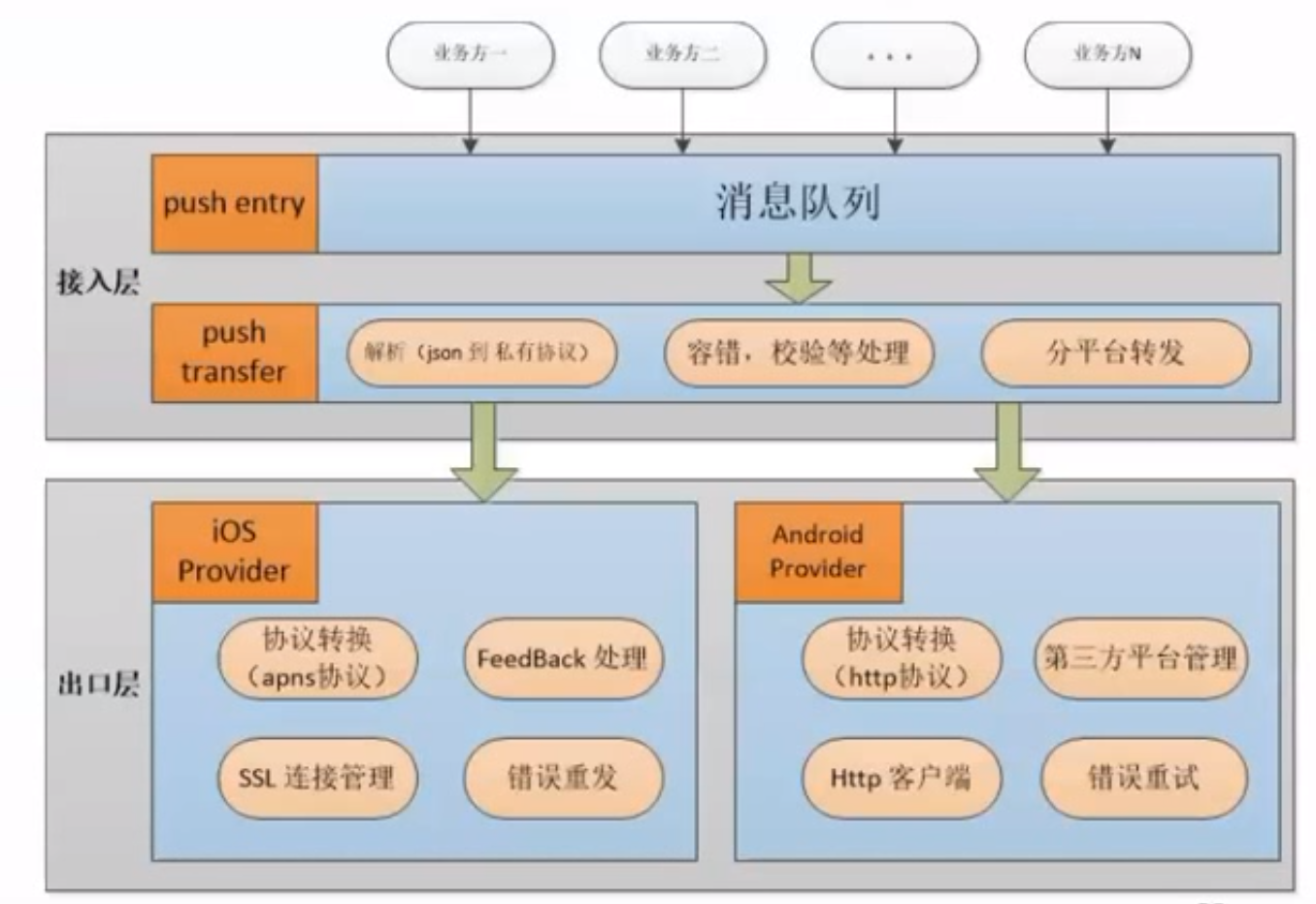
2.4.3 案例3:电商平台 C2C 转转
定位:全国最大的个人闲置交易平台
功能:用户、商品、社交、交易、圈子、推荐、
功能多
业务复杂
未来扩展
高可用
2.5【思考】高可用分层的潜在问题是什么?
- 我觉得:运维成本高。最短时间也比直接all in one要慢。以后开发比较复杂。
- 缺点:维护成本高,延迟,定位问题复杂度增加,定位时间增加
- 优点:可扩展性好
第三课:高可用硬件如何选择
这是软件开发人员的短板。大家都不是很熟悉。 主流硬件:
- CPU:
- 32processor(8物理核心,每核心2个处理器,开启超线程)
- 2.5GHZ
- 内存:
- 32G→64G→96G→128G
- 磁盘:
- SATA机械盘 → SAS机械盘 → SSD固态硬盘
- 价格10被
- IO性能50倍
- 读写越来越快 300M/s 读写都是很正常的。
- 硬件成本越来越高
- 1TB
- 网卡:
- 100mbs
- 1000mbs
cat /proc/cpuinfo
free -g //以G为单位
-
buffer和cache有什么区别?
-
从OS角度看还有多少剩余内存?从app角度看还有多少剩余内存?
3.1 如何选择硬件
 C6100 2U指什么? 服务器的长宽高和接口,U=就是这个规范单位。用于上机架用。
C6100 2U指什么? 服务器的长宽高和接口,U=就是这个规范单位。用于上机架用。
机型分类:
- 内存性质
- 8corex2 mem:128G Dis:SAS600Gx6 Raid5 //CPU一般,内存大
- 8corex2 mem:192G Dis:SAS600Gx6 Raid5
- IO性质
- 8Corex2 mem:128G Disk:SAS600Gx2 Raid1 + Intel S3700 800Gx6 Raid5 // 硬盘好
- 存储型:
- 8Corex2 MEM192G DISk 600Gx2 Raid1 + SATA 4TB * 12 Non-raid (Spark) //硬盘大
- 8Corex2 MEM192G DISk 600Gx2 Raid1 + SAS 1TB * 24 Non-rad /raid5 //硬盘大
- CPU计算性质
- 10Corex4 MEM:192G Disk:SAS 600G * 6 Raid5 // CPU核心多
- 8Core*2 mem:192G Disk:SAS 600G * 6 Raid5 GPU卡 //基于GPU计算
3.2 选择什么硬件
取决于业务场景:
| 业务逻辑 | 服务器类型 |
|---|---|
| web业务(tomcat,nginx) | 内存型/计算型 |
| 逻辑业务(判断,拼装等计算密集型) | 计算型 |
| Cache业务(memcached,redis) | 内存型 |
| 测试应用(测试人员测试) | 虚拟机(机器硬件过剩可以拆分成多个物理隔离) |
| 数据库存储型 | SSD |
| 实时计算Spark/Storm | 大规模存储SATA,对CPU内存不要求 |
| 离线计算场景Hadoop | 大规模存储SATA,对CPU内存不要求 |
| 海量存储文件,图片 | 存储型pulic |
| 图像识别 | 计算型GPU |
| 线下,边缘业务 | 虚拟机 |
虚拟机裸机:30%的性能消耗 宿主机重新也不影响应用,这才叫高可用。我完全可以实验。
3.3 硬件上如何保证高可用
- 传统企业级应用
- “IO1” :IBM大型或小型机 + ORACLE + EMC存储 // 价格昂贵,保证了高可用和性能
- 直接All in one 就好了。能保证一定可用性。
- 互联网打法
- PC级服务器(价格低廉)
- 1年down机一次是大概率事件
- 高强度读写普通磁盘,损坏概率更高一些
- 硬件可用性进一步下降
- 怎么做到PC级服务器高可用呢?
- 尽可能采用配置比较高的服务器。生命周期比较长。
- 没办法的话,就改善磁盘NAS等,SSD等。 关注磁盘高可用。数据是最重要的。
- 磁盘:
- SATA:串行ATA。 ~10M/s
- SCSI:小型计算机接口。
- SAS :串行接口。
- SSD :功耗小,耐震,耐高温。贵。 是SATA的50倍 300~500M/s
- 对磁盘的高可用:
- Raid(磁盘阵列):价格便宜的磁盘构成磁盘组。并行读写 + 冗余备份。提高性能和可用性。
- raid 0 :拆分文件,并行写入。加速读写,没有冗余备份
- raid 1 :只做冗余备份。 可用率 50%。
- raid 2 :
- raid 5 :每个磁盘都是单独校验。有一个块磁盘坏了没问题。
- 可用率:所有磁盘减去一个磁盘。
- 速度: 4硬盘raid5是raid 0的速度,比三硬盘更快。价格差一倍。
- raid 6 :几乎同上。性能更佳。允许同时坏两块硬盘。
- raid 10 : Raid0 + raid1的结合。先顶层Raid1 在 底层Raid0. 才具备可用性。 可用率50%
- Raid(磁盘阵列):价格便宜的磁盘构成磁盘组。并行读写 + 冗余备份。提高性能和可用性。
- 单机层面保证磁盘高可用
- 系统保存数据:RAID/SAS
- 系统不存储数据 : 不Raid
- DB : Raid /固态硬盘
- 如果是整个机器挂掉了
- Raid的优化
- 词条元素大小 8kb,16kb,32kb,64kb,128kb 越大性能越好
- 读写策略:fore wb with no battery
- 单机+raid还是不靠谱,怎么办?
- 系统多机冗余 (普通PC服务器:Dell R410,R420,C6100,R710,1950,R720)//几千块钱一个万元以内。
- 数据多机冗余 (设计到数据同步)
- 保证高可用性
3.4 最佳实践
- 单个机器: 普通PC服务器
- (普通PC服务器:Dell R410,R420,C6100,R710,1950,R720)
- 内存型 128GB
- 硬盘型 SATA → SAS → SSD
- CPU型 2.5Hz 16core → 32 core → 64 core → 128core.
- 在磁盘上做一些Raid,挂载在PC服务器上
- 多机冗余(上面的那种机器)
- 模块数(就是应用程序)
- 至少两个节点,取决于吞吐量和单机吞吐量。
- 存储
- Master-slave 例如Mysql。读写分离。写在主,读在从。提高性能。
- Replic-Sets 例如MongoDb。可自动恢复的MS模式。
- 模块数(就是应用程序)
- PC级服务器(价格低廉)
作业: 假设1000w记录*1kb。bmsyql,ssd。假设3kqps/TPS。读写比例10:1。问数据库能抗住吗?需要加缓存吗?
QPS:每秒请求次数 TPS:每秒交易完成次数 每秒3kQPS = 主要看写需要每秒多少M。 每秒 3k个请求(DB操作) * 0.1 = 每秒写的请求数 = 300约等。 每次写一条记录的话 ,每秒写入的数据 = 300 * 1kb = 0.3M/s 看起来还行啊。估计不是这么算的。
思路:考虑硬件读写速度。300M/s ssd的极限,ssd加上数据库后也就200M/s 3000qps 每次读1条数据 3000 * 1 * 1k =3M 每次读10条数据 3000 * 10 * 1k =30M
不用加缓存。
改善方法: 单机的话:加缓存 多机的话:数据库垂直拆分,多机拆分。
https://blog.csdn.net/qq_29347295/article/details/85116229
3.5 思考:企业自己搭建私有云架构还有没有必要,还是统统所有业务都直接上阿里云完事?
不能上阿里云共有云的:
需要提供给国家审查的 自己需要800多个节点的,私有云(openstack)会比公有云便宜 需要更高性能的时候 想控制权
什么适合放在共有云上
不太重要多的研发系统和测试系统 没有预算的小公司最适合上公有云了。用公有云的Paas或Saas开发点程序就挣钱。 有钱的公司,且规模需求大的,还是私有云便宜。
谁一直在公有云上
初创新公司,从诞生那天开始就在公有云上。他会一直用公有云。也很香。
有哪些方案,成本和性能如何
|方案|成本|性能| |—|—|—| |私有云|最高|中| |公有云|居中|高| |ICD|最低|低|
结论:
没钱的,直接上公有云。别搞什么私有云。 有钱,没规模,直接上公有云。 有钱,规模需求大的,800节点以上,私有云。 巨私密敏感数据,私有云。 数据无所为,上公有云。 既然公有云初级阶段就可以上,测试开发都可以上,所以,一般公司都有公有云。等上规模或做大规模程序节点中多的时候,放到私有云,最后,公司既有公有云又有私有云(混合云),需要更高技术团队来维护。
第四课,DNS高可用?自己的DNS服务器?
什么是DNS,DNS原理(Domain Name System) 将域名转换成IP
DNS服务器:分布式服务器
DNS协议:
- Time to live :到生效开始的时间
- Type
- A: ipv4
- CNAME :别名 (另外一个域名)
DNS解析过程:
- 首先查找localserver【运营商:电信,联通,移动】
- localserver有就直接返回给你,没有就查找rootserver
- rootserver返回权威服务器地址
- localserver继续查找权威服务器
- 最后由localserver返回给你地址
域名缓存
不变化的域名:1周 不断变化的域名~ip:半小时 (time to live)
域名查找工具
dig www.baidu.com -t A +short //查找域名对应的A记录(ipv4)
dig www.baidu.com +trace //从跟域名到自己的域名服务器经过的所有域名服务器
4.1 传统DNS会有什么问题
-
2009 巴西银行被DNS劫持,被钓鱼
-
2010 百度域名被DNS劫持,百度主页访问不了一上午
-
2012 日本三井银行被DNS劫持,钓鱼攻击,导致800万用户感染病毒
-
2014年中国顶级域名故障,大部分网站无法访问。有一家公司却可以被访问,他们采用了DNS高可用。使用本地预知IP?
损失:
-
- 经济收入
-
- 公司形象和品牌形象,股价
-
- 技术实例的损失
4.1.2 DNS劫持: 域名服务器不保证映射是否正确
所以,黑客修改local server把某域名设置成另外一个A记录。 返回给客户错误的地址。
被黑客恶意修改了数据库。
例如,被竞争对手或流氓软件,引导入别的网页。赚取流量或干脆不让别人访问你的网站。
如何查看域名对应的地址呢?
nslookup gitlab.ccbjb.com.cn //查看对应域名解析出来的IP
看这个ip归属于谁
- linux
whois 61.135.169.121// linux - windows上直接网页查看ip归属
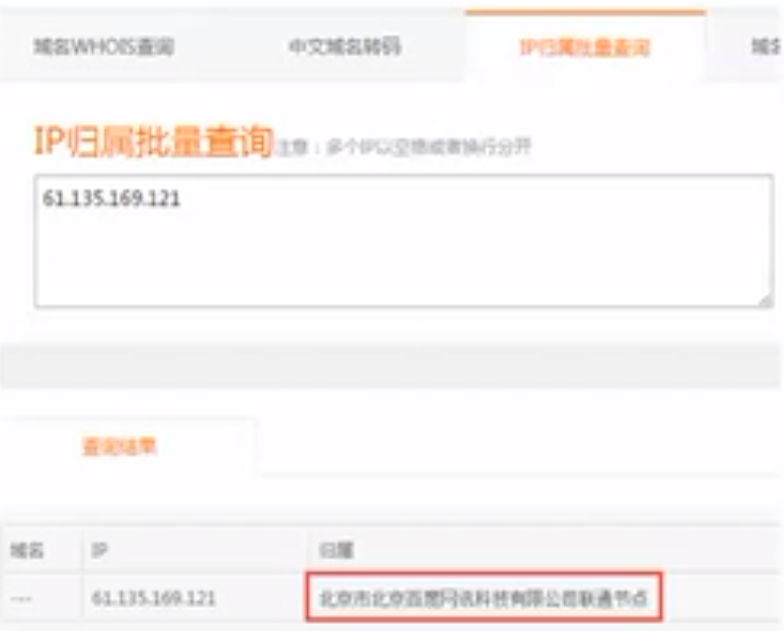 如果不是百度的,那就被劫持了。
如果不是百度的,那就被劫持了。
4.1.3 DNS欺骗
用一个假的DNS应答 对个人来说,很难发现。运营商来发现这个事情还是比较简单的。
如何发现有没有被DNS欺骗呢? 1.首先nslookup查看ip拥有方,查ip看ip拥有方。 和DNS劫持一样
4.2 DNS防止被劫持的手段
数据合法性验证:应用级别的。校验是不是我希望的数据,数据格式的校验。例如,socker包解包的验证码iso8583包。 监控(同上):应用接口的返回值和预想的不一样。例如,返回用户列表和以前的不一样或格式都不一样。
解决:商务同学(就是网管)投诉localserver DNS拥有方。
不太可能让用户主动选择DNS服务器的方式,不现实。
DNS解决方案:
4.2.1 直接使用IP地址
不使用域名,不用解析域名。那就需要在客户端预置ip列表。 DNS服务器有时充当了负载均衡的功能。
直接指定IP之后,负载均衡功能就丢失了,怎么解决呢? →:客户端(安卓,ios端)得负责负载均衡。
- 随机访问某个ip。
4.2.2 HttpDns
DNS协议也是http协议。 DNS协议的端口是53. 绕过DNS协议,解决运营local DNS劫持问题。
使用HTTP协议来解析域名。
增加一个HttpDNS服务器。
万一HttpDns服务器挂了,就用原来的方式DNS协议访问与英商的localDNS服务器。

好处:
- 省掉了域名解析的过程。
- 更安全
需要引入SDK
- 在安卓或ios客户端程序上需要特俗的SDK。
4.1.4 流量劫持
- DNS劫持
- CDN劫持
- 网关劫持
- 随心所欲
- HTTPS
- SSL
- 加密
→ 尽量https机密
4.3 高可用DNS如何设计
- 移动方向
- 选用httpDNS
- 基于IP地址直连
- 其它方向
- 使用IP地址直连
- 监控
- nslookup
- 投诉联通你dns被篡改了。
- 传统DSN监控,及时报警
4.4 高可用DNS最佳实践
4.4.1 案例1:IM
需要TCP长连接
传统DNS就不能满足要求了。每次随机一个IP
DNS解析优化:
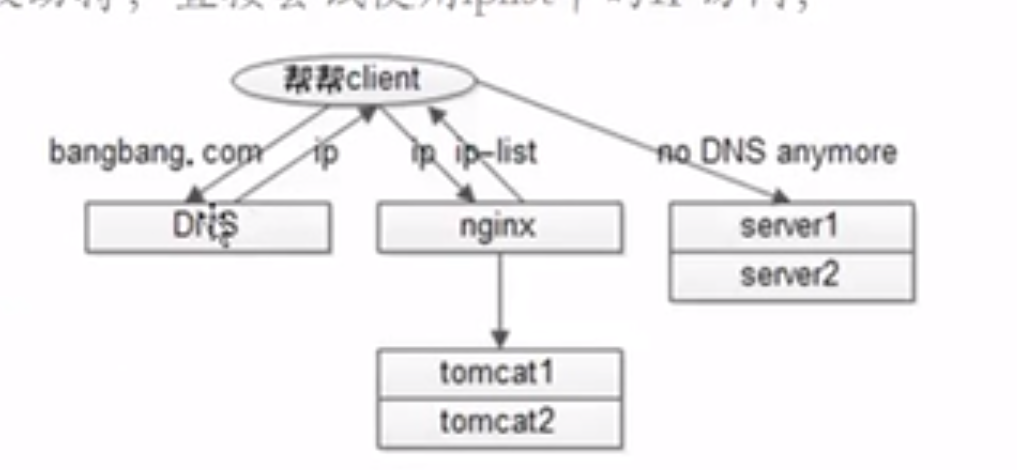
客户第一次,通过域名拉取iplist 以后就不访问了。 如果DNS被劫持,就通过iplist来访问。
问题:
- 复杂均衡问题
- APP随机选择ip-list中的一个即可。
- 扩容nginx增加一个后端服务器,没有影响。如果不用nginx,怎么水平扩容,增加一个ip
- 在httpsDns服务器上增加一个ip
- 每次都访问iplist,费流量也容易被劫持
- 增加httpsDns的iplist版本号,本地和服务器上iplist对比版本号(时间戳)。一样就不拉取。不一样就拉取。
- 省流量,省电量。
- nginx不好做异构服务器的负载均衡。但iplist可以增加一个权重。app随机ip的时候,用权重来随机ip。类似抽选。
4.4.2 案例2:流量劫持,应用中插入东西
流量劫持
A公司的手机APP上,出现了别的公司的广告。
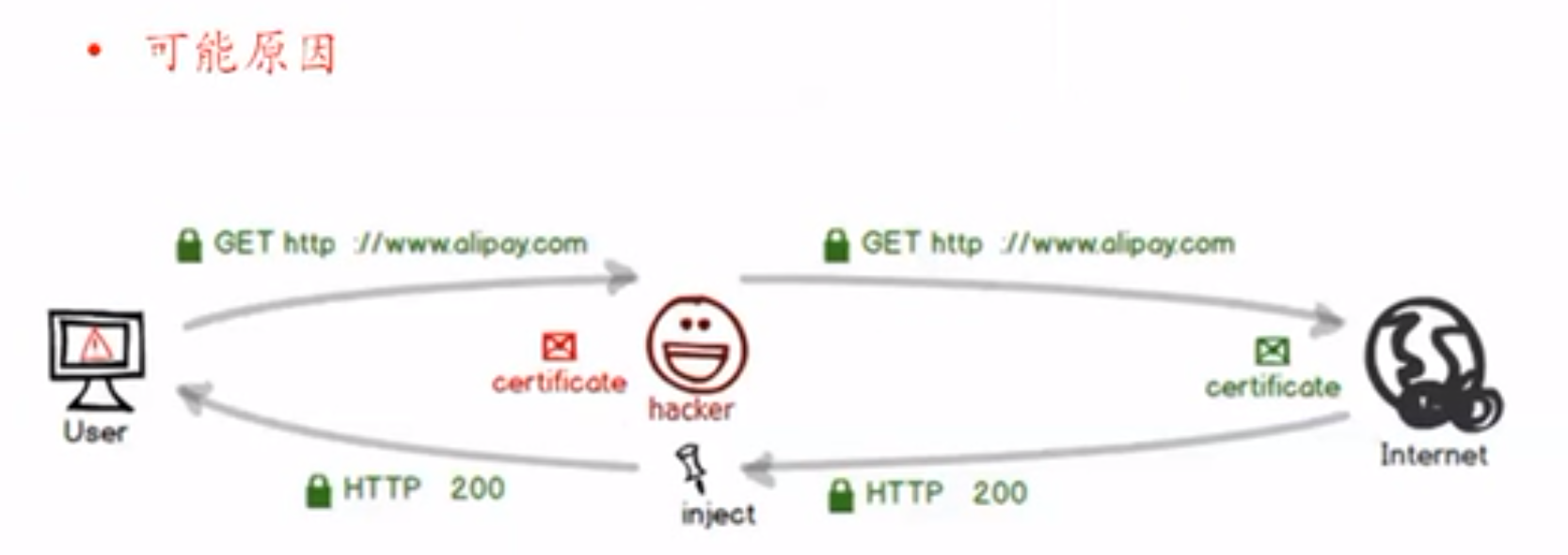
hacker注入了广告。转包给你。
#### 4.4.3 案例3:链路修改,把你的请求修改掉
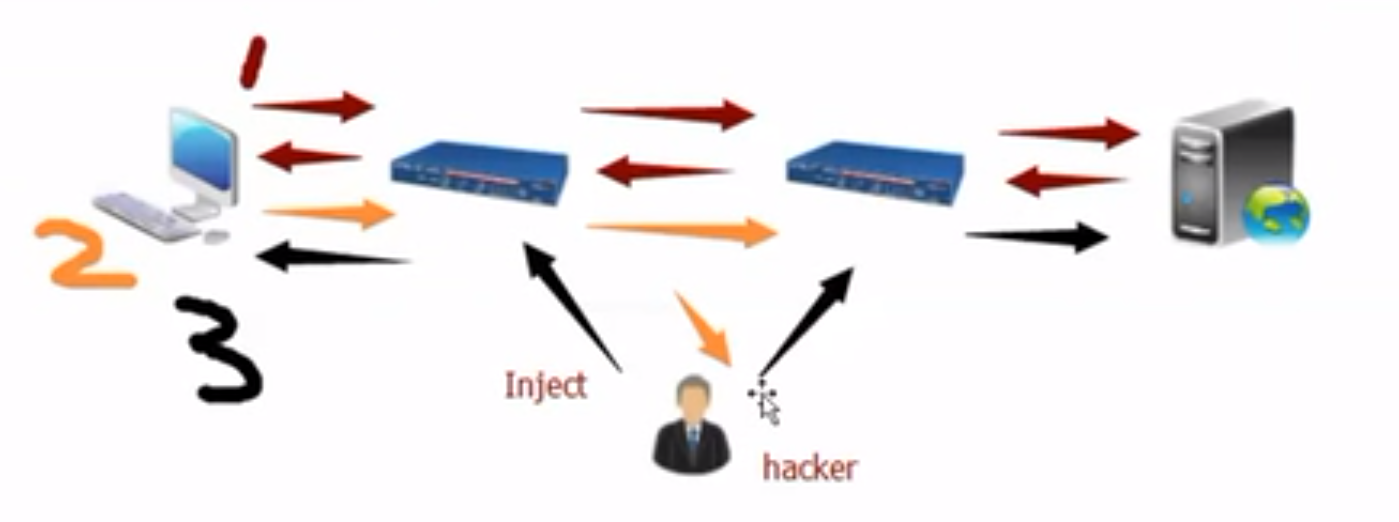
复制一份请求出来,发一个reset请求,到服务端,关掉服务,于是hacker拿到请求控制权, 返回给你任意消息。
- 通过某个网关,复制一个请求。
- 发送reset请求给服务器
- 给你发随意的字符串
4.4.4 【作业】在应用层是否能被修改?
第五课 CDN加速系统
CDN: content delivery network ,内容分发网络。 Origin:你的源站点。 加速站点:从Origin拷贝静态文本。
一般缓存静态资源,永远不会变化的资源。 css,html,image
5.1 CDN技术点
CDN架构:
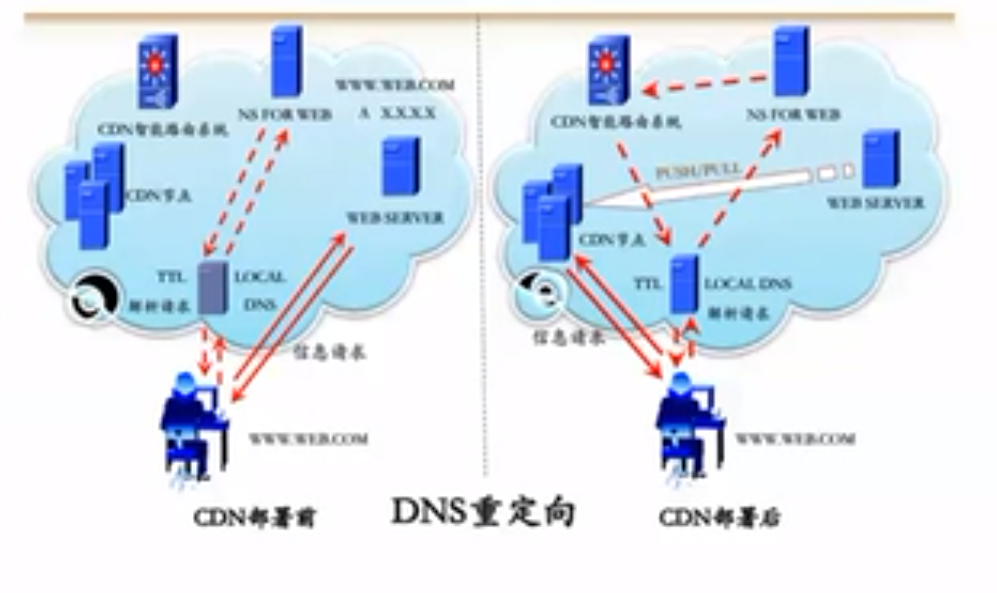
先走传统DNS,localserver返回CDN CName,访问CDN。 经过全局CDN节点平衡器。获得CDN的IP 获取最优的CDN节点IP。返回给用户,用户范围该CDN节点获得内容。
CDN没有内容,就访问origin CDN有内容,就返回内容。
架构的概念
- 全局负载均衡器
- 局部负载均衡器
- CDN节点
CDN也是很多机器,很多内容。
- 内容的监控机制。
- 内容的缓存和存储
- 源内容存储:
- 用分布式存储系统,因为存储的内容比较多。
- CDN内容存储:
- 支持各种格式
- 缓存命中率高
- 可靠性
- 稳定性
- CDN内容管理:
- 提高存储利用率
- CDN本地内容索引
- CDN本地内容拷贝(主从)
- CDN本地内容访问状态信息收集
(没有深入展开)
内容分发: 源服务器怎么放到CDN
-
方法1 :主动分发 Origin push to CDN 有改动就主动同步数据到CDN
-
方法2:被动拉取 CDN pull from Origin 用户请求CDN,没有内容,就从Origin获得并缓存起来。
CDN的路由
路由把请求分配到对这个用户来说的最佳节点 离用户最近 CDN节点的负载比较低
所以,第一,全局的负载均衡器。 第二,本地的负载均衡器。
负责路由和分发。
实现方式:
- DNS
- 应用层重定向
- 数据层重定向
关键技术
- 索引建立
- 缓存,
- 推送,
- 组播技术
协作式推送技术
- CDN节点上数据共享
- 避免了复制和更新的成本
- CDN维护CDN节点与源内容的映射表
- 源主动推送内容给CDN
非协作式拉取技术
- 重定向到最近的CDN
- 有内容返回
- 没内容向Orign请求内容
协作式拉取技术
- 用户重定向到最近的CDN节点
- 有内容返回
- 没内容向其它CDN请求内容
- 其它CDN没内容,再想ORigin请求
- 减少了Origin带宽
- 现在还不成熟
5.2 为什么使用
- 加速请求静态资源
- 缓解Origin访问压力
- 解决了跨地区跨运营商速度慢的问题。
- Origin在北京。用户在广州。没有CDN需要很长的链路才能走到。
- 用了CDN,离用户很近。就不用那么长链路了。
- 突然迸发的流量
- 例如618,1111. 会弄挂Origin
- CDN能解决一些问题。
- 合理利用互联网资源
- 在放点别的资源到CDN
- 防止单点故障
- 当然Orign不可能是单点。
- 就算Orign会挂,你还能访问CDN
- CDN统计了用户反问信息。
- 统计了用户行为。
- 防止黑客攻击 ,why? DDOS
- 没有CDN,所有请求就到Orign
- 有CDN,CDN多节点能平均分配Orign。降低了DDoS攻击的强度。
-
还可以对直播 做CDN ? <font color=red>直播呀!!!</font>
- 对中小企业租用虚拟服务器慢的问题
- 虚拟机
- 云主机公用
- 加速访问
- 解决加速问题
- 静态图片
- 静态文本
- 静态视频
5.3 发展历史
三代:最早源与代理服务器,服务器集群技术。
第一代,静态内容加速 第二代,视频也可以加速了 第三代,基于社团(一些共享协作)的CDN
5.4 国内应用
- 大型网站
- 自建CDN
- BAT、京东
- 中小型网站
- 第三方合作(要求的质量没有那么高)
- 蓝X,网易,世纪华联
- 小网站
- 不用CDN
L1-cache:最核心,最访问频繁的 80%的数据量。但是站整个量的10%
L2-Cache:次核心的数据。站总量的10%。
最热点最核心的数据放到最外层。
5.5 应用领域
互联网应用:
- 流媒体应用
- 视频点播。录好视频放到某个点
- 视频直播。通过CDN来做。网红直播。推流到CDN上。
- 大文件下载
- 图片,视频,文件
- 门户网站→社交网站
- QQ,默默
- 电商网站
- 商品详情
- 商品描述
- 商品图片
CDN业务升级
- 性能提升
- 数据智能调整
- 流量管理
- 负载均衡
视频服务
- 最关键的服务之一。2005年就开始了。
- 允许下载和上传视频
IPTV三网融合
- 2005三网融合
- 运营商发展视频
流媒体对传统网络冲击
- CDN保证Oos
- 环节流媒体对主干网络冲击
适用场合:
- 静态内容加速和分布
- 动态内容静态化
- 页面,脚本
- 静态内容和动态内容分离
- 静态图片
- 动态数据
- 动态内容静态化
- 页面 html,html,shtml
- 图片
- 流媒体:mp4等
- 脚本 :css,xml
- Apps,安装包。
5.6 数据一致性
分发方式:
- 主动分发:
- 分发控制器去源站抓取
- 提供用户上传接口
- 不存在数据不一致问题
- 被动抓取
- 缓存更新不及时
- 数据不一致问题
- 设置缓存失效时间
- 2个小时
- 能解决最终一致性问题
- 可能会出现2个小时脏数据
- 强一致:还是要主动分发来解决
- 或缩小缓存缩小时间
- 或增加数据版本号。
- 版本号低了就去pull。
5.7 实践案例
CDN选择:
- 第三方合作
- 腾讯
CDN高可用保证
- 版本号控制
- 图片,每次上传图片不同url不同。
- Apps分发
- 版本号控制
- 错峰分发
- 保证了CDN带宽
- 客户端随机一段事件sleep 再去访问。
- 多种渠道App分发
- 几百个渠道
- Apps包一样,需要区分渠道号
- 点击下载js动态获取渠道号,下载对应渠道号App版本
第六课
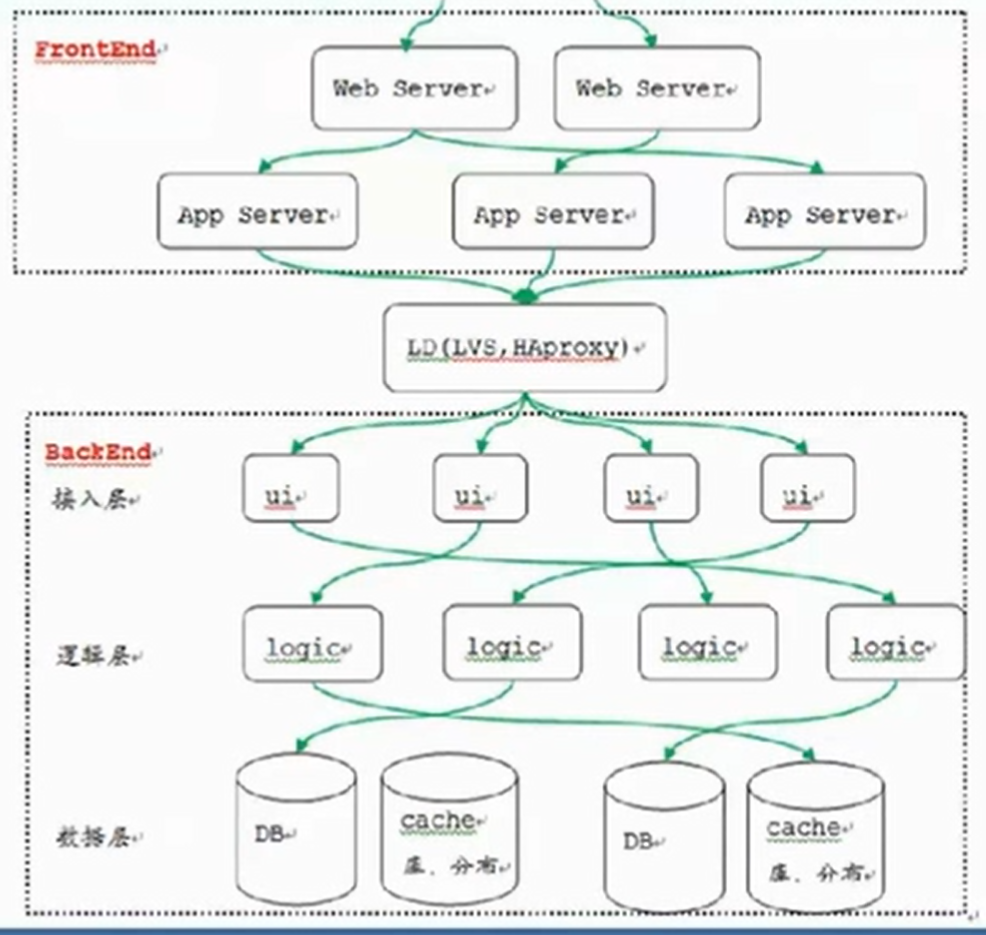
6.1 互联网产品通用架构
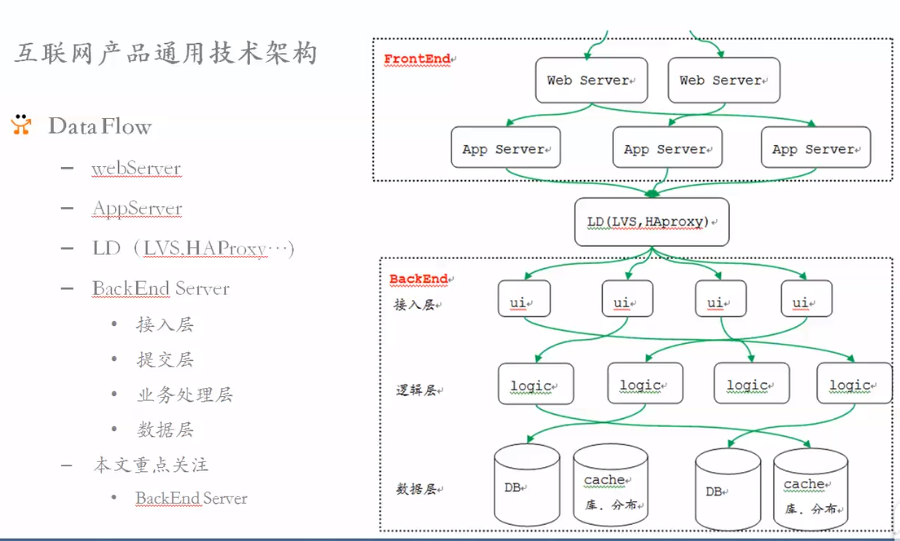
百度某应用:
- front:
- web server
- app server
- backend
- ui 接入层
- 验证身份
- 转发请求
- 接受logic再返回给front
- logic
- DB,cache
- ui 接入层
IM
- 请求同时在线100W+
- 机器:百台+
- Java/CPP
- 定位:传统IM
- 核心功能:
- 用户关系
- 添加好友
- 发送消息
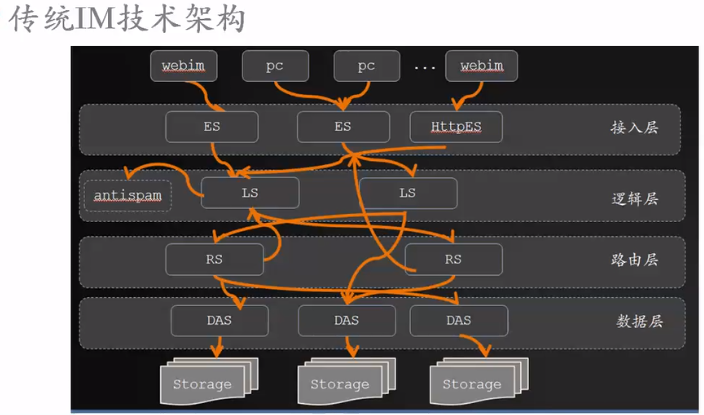
接入层和webim建立长连接的请求。 号称百万的长连接。
A用户要发消息给B A→路由层(用户这次请求的状态信息,ip等)→接入层→B
-
无状态设计,每一层都不存储状态。
-
每层模块动态高扩展
-
模块冗余,高可用性保证
-
动态负载均衡,动态切换可用服务节点
-
优化效果
-
单机支持50W在线
-
单机线上3w+qps (每秒三万多请求)
-
转转:
定位:电商,二手交易平台
- 用户管理
- 商品管理
- 社交:留言,评论,聊天
- 交易
- 圈子
- 推荐
- 搜索
- 运营
百度feed系统
好友动态
获取好友的feed
组合好友的feed聚类展示
按照时间倒叙展示
push or pull
- pull
6.2 接入层作用
接入层:
- 管理客户端http/tcp连接
- 数据合法性校验
- 建立加密通道
- 整合少量长连接
- session管理
- 初步的攻防(长久不发消息就回收连接)
- 转发到逻辑层
6.3 接入层Session设计
- session是什么:请求读取的上下文。
- 高可用是基于服务无状态
- 显示中业务都是有状态的。都得放到session。就是有状态了。
- 都得记录用户信息
- 记录用户的购物车信息
- 这些信息随着用户操作而变化
- 这怎么办呢?
单机环境设计
- 单机不存在session共享问题
- 处理比较简单
- sessin放在本机内存
- 高可用无法保证
- 服务进程挂掉
- 宕机
- session丢失,不可用
- 怎么搞??????
集群设计
session复制
- 集群所有节点的接入层服务器之间同步session数据
- 每台都保存全量session数据
- 用户请求只需要访问其中一台,读取数据最快
- 高可用邦长
- 部分机器宕机,没影响
负载均衡→session共享→接入层(多台),复制session
session复制的问题:
- 占用cpu和网络资源
- 所以适合接入层集群比较少的
- 存储全量信息对内存占用比较大
- 对大量集群(千台,几千台)经常会内存不足。session复制就不合适。
session绑定
- 一个用户的信息,只存在一台机器上,再复制到另一个台上。master-slave
- 根据就用户请求(UID)HashID
- 特定用户请求路由到特定接入层设备
- 部分网站使用
- 高可用如何保证
- 单点问题是存在的。但可以用下列方式解决:
- 复制机制 来解决单点问题,例如,写完一台之后复制到了另外一台
- 单点问题是存在的。但可以用下列方式解决:
session 保存到客户端
- 客户端保持session存储到客户端
- 每次请求携带客户端session
- 服务端更新后送回客户端保存session
- c/s
- aoos
- 记录到native中(sqllist)
- aoos
- b/s
- web - 记录到cookie
- 这种方式,接入层不再保存任何session信息。
- 问题:
- webcookie记录信息大小限制,例如100KB
- 每次都要传输session,流量性能收影响
- 用户关闭,清理session时用户请求不正常
- 好处:
- 方案简单,支持服务端无缝伸缩
- 方案可用性高。
- 较多网站都有使用
结论:这总方法也不好
session高可用
- 接入层无状态话
- 统一的高可用session服务器
- 接入层分布式读写session集群
- 状态分离
- **接入层本身无状态
- session集群有状态**
- nosql(memcached/redis)
- rdbms(mysql/mongoDB)
(
接入层都是无状态
session 绑定方式的寻服务器方式,用户ID hash来寻找服务器
session 集群,三个节点以上,每个节点包含一个master机器和slave机器
SM1 + SM2 + SM3 + …
)
—
6.4 接入层数据安全
1. 传输的数据解密
https
- 单项加密:
- 不安全,
- 中间人攻击
- 双向加密:
- 安全
- 客户端证书
- 配合
接口分级
- 配合
- https
- https + 短信验证
2. 连接的通道加密
解决客户端和服务端加密,有个适合一切客户端你的方法:
先解释名词:
- 对称加密:加密和解密是同一个密钥,ASE
- 非对称加密:加密和解密使用一对密钥,RSA
- 公钥: 给别人加密用
- 私钥:解密用
技术实现方案
- 客户端-服务端所有请求都得加密。
- 加密效率低
- 采用对称加密
- 对称密钥怎么生成?
- 使用非对称加密算法两次协商确定
- 安全信道必须满足
- 第三方无法伪造服务器
- 截获了也无法解密
- 加密效率低
- 具体怎么做呢?
- 客户、服务端都必须有随机生成密钥的过程
- 四步握手
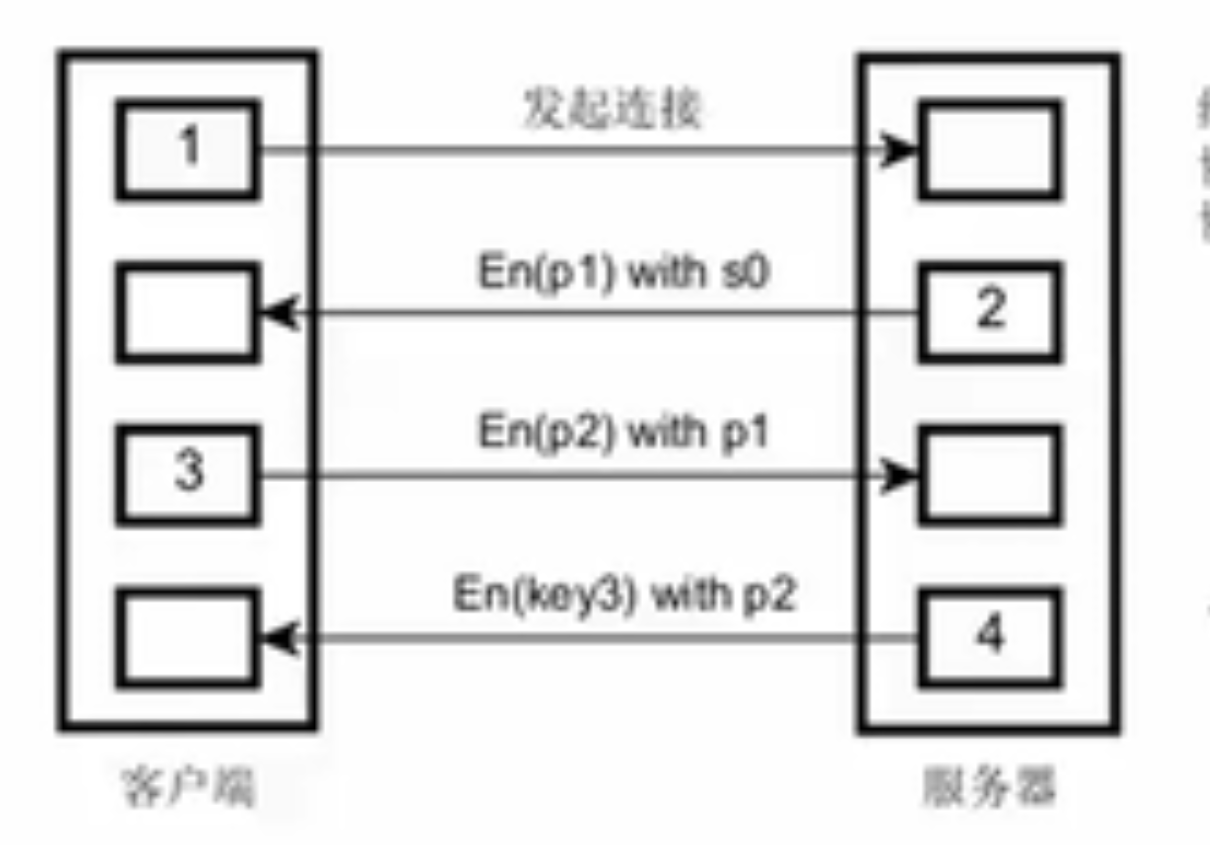
- 写死在代码中的公钥0(公钥池,每次选一个)
- 就是多用不同公钥传输几次,最后把key传给客户端
6.5 接入层数据正确性
- 数据明问题
- 截获也没有用
- 但是:数据篡改无法避免
- 数据正确性需要保证
- 如何保证?
- 数字签名,对数据签名
- md5或者更复杂的签名方法
- 过程
- 客户端月订签名
- 服务端生成md5验证码
- 一致ok,不一致,说明被篡改。
- 如何保证?
例如,双方才知道的key,必须保密
核心:模块和数据分离。模块成无状态。就能动态伸缩。 状态(session)同一分布式存储 数据冗余保证
6.6 接入层高可用设计方案
无状态 动态扩展
6.7 接入层高可用设计最佳实践
模块和数据分离
session绑定
- 每个session同步复制
不存储session
- 接入层不存session + 客户端存储session
-
6.8 我们的实践案例
第七课,业务逻辑层设计
接入层→逻辑层(→路由层)→数据层
7.1 逻辑层都做什么
实现业务功能。不是基础架构,而是真正商务需求的逻辑在这实现。 该层是一个无状态的api接口服务器?RPC?Dobble?集群?每台都一样?
还是?一个逻辑上的层。一写类,springboot内部的概念? logicClass?
还是两个类?多个类?都在一个工程里,一个服务器里?
可以是一个文件(一个类) 可以是多个文件 可以是多个服务器,一个业务一个进程
7.2 逻辑层整体架构
|方式|说明|缺点|应用场景|
|:—|:—|:—|:—|
all in one 方式|一个文件|耦合,开发维护成本大,牵一发动全身|创业初期或业务不复杂
all in one 方式|一个类|耦合,开发维护成本大,牵一发动全身|创业初期或业务不复杂
all in one垂直划分|一个业务一个组件(目录或类)|利于开发维护,业务不互相影响。
缺点:物理上是一个模块,编译成本高。一个业务修改都需要重新上线,重启影响所有业务,即使滚动更新也会影响|一般脑子没病都会这么做,互联网公司有的多,58和百度都这么用,对日项目基本都这么做。本质上,每个业务还是没有隔离。
业务建物理垂直划分| 每个业务独立的进程(微服务?)
商品进程
用户进程
客服进程| 重启上线都不互相影响,业务间完全解耦。单独开发单独运维,开发运维效率高| 58,百度开发大规模时也用
7. 3逻辑层无状态怎么设计
系统不存储数据,不存储业务的上下文 每次都是请求携带数据进入逻辑(逻辑里不存储数据,只是处理数据) 子系统之间完全对称(服务器之间,是无状态) 请求提交到任何服务器,结果都一样
就可以随意伸缩
- 关键因素
- 不保存请求数据
- 不保存逻辑数据
- 所有业务逻辑层完全对称
- 一台或多台宕机没影响
- 请求可以提交到任意一台服务器
- 业务逻辑层高可用
- 实现高可用的关键因素
- 实现负载均衡 (1s超时没返回再选择其它的服务器)
怎么负载均衡 【LVS/nginx】
- 实现负载均衡 (1s超时没返回再选择其它的服务器)
- 检测服务器可用状态
- 自动转移失败机器
- 请求量和需求量较高,流量自动分配到集群中多态服务器
- 心跳发现服务器不可用,剔除掉
- 一旦服务器可用,可以自动重新连接恢复
纯异步调用
- 什么是同步:阻塞式
- 什么是异步:不阻塞。多线程处理完后回调通知调用者。或用状态来通知。
- 优点:吞吐量高
- 缺点:实现成本高
- 为什么异步化
- 提高吞吐量,减少延时,避免浪费时间
- 怎样实现异步
- 消息队列
- 例如,用户注册写消息队列返回给客户,然后逻辑层读消息队列写DB与发邮件同时做。做。
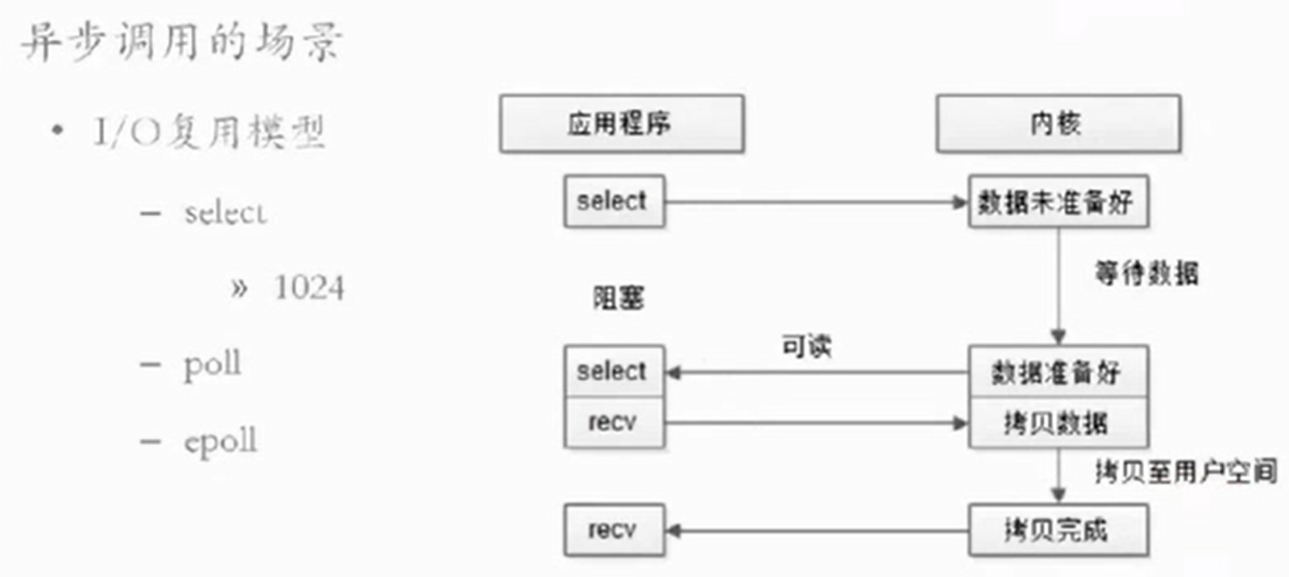
- 异步调用的场景(CPU等待IO,效率低,不够优化)
- IO
- 网络IO
- IO模型
- 阻塞IO模型 : 下一步严重依赖上一步。必须阻塞
- 轮询非阻塞模型:下一步轮询看上一步是否准备好。效率也不高。
- IO复用模型:多多个句柄管理。select是阻塞的,recv是异步
- 高性能纯异步调用
- sever但连接池,server端收发队列
- client端连接池。client端手法队列
- 超时队列和超时管理起
- 上下文管理器+状态机
- 消息队列
7.4 逻辑层如何分级管理
硬件层面
- 核心系统用好的机器
- 边缘系统用差的
部署层面
- 服务部署隔离
- 避免故障带俩连锁反映
- 核心系统在物理机
- 核心系统在不同机房
- 边缘系统用虚拟机
- 边缘系统私用公用机器
监控
- 核心监控,邮件短息通知
响应分级
- 核心,优先响应,优先开发
7.5 逻辑层如何设置合理的超时
为什么设置超时
下游死了,线程死锁了,请求得不到想用 请求占用资源 调用方得不到响应,体验查
怎么设置?
- 平均响应延迟的2倍。避免长时间等待
- 响应延迟高,超时设置长协
- 响应延迟低,超时短些
- 继续重试
- 一般三次
- 多次五好处
- 请求转移到下游其它同样服务器上
7.6 逻辑层服务降级如何设计
问什么有时需要服务被降级?
- 网络高峰期,并发量大
- 服务能力有限
- 宕机
- 服务雪崩
- 保证核心服务正常使用
做降级
- 保证核心服务有用
-
对非核心服务弱可用甚至不可用
- 降级方案:
- 拒绝部分请求
- 队列方式:入队列出队列时间,超过一定时间,直接返回
- 优先级请求方式:非核心请求直接丢弃
- 随机拒绝:
- 随机丢弃一定比例的请求
- 网站一会好用一会不好用,大概是这样处理的。
- 关闭请求
- 非核心业务直接关闭
- 业务逻辑层屏蔽掉(关闭社交,私信,留言,评论)
- 拒绝部分请求
7.7 逻辑层如何做到幂等设计
- 请求失败后会继续重试
- 保证服务重复调用和异地调用结果相同
- 不能保证幂等性(交易必须保证幂等!!!!!!)
- 结果将是灾难性的
- 转账
- 交易
- 支付
怎样做到幂等
- 结果将是灾难性的
- 天然幂等
- 离线消息设置为已经读取
- 非天然幂等 (必须去记录状态)
- 支付
- 支付ID,支付状态
- 每次支付钱,判断支付状态,未支付才转支付
- 转账
7.8 逻辑层高可用设计最佳方案
分布式锁 分布式事务
- 支付
7.9 逻辑层我的实践案例
思考:网络编程我还是不熟悉,否则我应该能懂。
第八课,数据存储层设计
8.1 高可用架构数据存储层 重要性
命根,一定保住
数据才是真正财产, 技术服务不是
8.2 高可用架构数据存储层 单机
存储引擎,是存储系统的发动机。
- 支持: CRUD
- 类型:
- 哈希
- 数组 + 链表
- 支持CRUD ,还有随机读
- 快
- O(1)复杂度
- 例如,Mysql,Oracle
- B树
- B Tree
- 支持CRUD
- 支持顺序扫描,范围查找
- Mysql,InnoDB聚簇索引
- LSM
- Log Struct Merge Tree
- 增量修改保存在内存中,达到一定条件,才批量写入磁盘
- 读取:需要磁盘+内存 →返回给用户
- 好处:提高写入性能
- 缺点:读需要磁盘+内存
- 重启后会不会内存丢失? 不会
- 内存丢失也会从commitlog恢复
- 例如 Level DB
单机存储原理
- 哈希
- 数据模型
- 模型分类:
- 文件: 操作系统
- 关系 :DB
- 图:InfoGrid,Infinite,Graph,Neo4j
- kvalue:redis memcached
- 列:Cassadra,Hibase
- 文档 :mongoDb,CoachDB
- 模型分类:
- 原理:
- 事务与并发控制
- 锁粒度
- 数据恢复
- 操作日志
多机存储原理
- 操作日志
- 事务与并发控制
- 数据分布在多节点上,需要负载均衡
- 数据分布方式
- 静态方式
- 取模:静态Hash
- uid%32 :
- 动态方式
- 一致性hash
- 有:数据飘移问题
- 静态方式
- 复制:
- 分布式存储多个副本,例如HDFS
- 保证了可靠性和高可用
- CommitLog 一旦有问题可以回滚
- 故障检测
- 心跳
- 数据迁移
- 故障恢复
FLP定理和设计
1985年FLP不可能
- 异步通信不存在任何一个一致性算法。只能取舍。
- 出现了CAP定理 2000年
- 一致性C、可用区A、分区容忍性P(一定要保证)
- 保证一致性
- 强同步复制
- 主副本网络异常,写操作阻塞,可用性无法保证
- 保证可用性
- 强一致性无法保证
- 异步复制
- 保证了存储的可用性
- 权衡 (一致性CP 和 可用性AP )
- 金融强调 :强一致性CP
- 消息系统: 保证可用性优先 AP
- 2PC协议:解决多个数据分片上操作原子性
两阶段提交
- 实现分布式事务
- 两类节点:协调者1个(备份协调者),参与者多个
- 每个节点都记录CommitLog,保证数据可靠性
- 两个阶段:
- 请求阶段
- 提交阶段
- 应用:分布式事务,
- 缺点:无法处理协调者宕机
- Paxos协议:解决多个副本上一致性
- 主节点挂,选举主节点
- 角色
- 提议者
- 接收者
- 执行步骤
- 批准
- 确认
- 批准
- 可以处理协调者宕机
- 2PC和Paxos结合使用。
8.3 高可用架构数据存储层 冗余如何做
- 多个数据副本
- 复制:mysql 、mongoDB。maser-slave,没有主动恢复
- ReplicSet: mongoDB
如何做:
- 双写 写主也写辅
- 分布式事务保证读写。性能下降很多
数据备份:
- 冷备份 传统做法,保证不了高可用
- 热备份 online
- 异步热备份:写完主就返回。之后主慢慢写从。Mysql,mongoDb
- 同步热备份 :写完从才返回。性能低
8.4 高可用架构数据存储层 数据无缝迁移
都是蜻蜓点水般讲解。
mongo → mysql
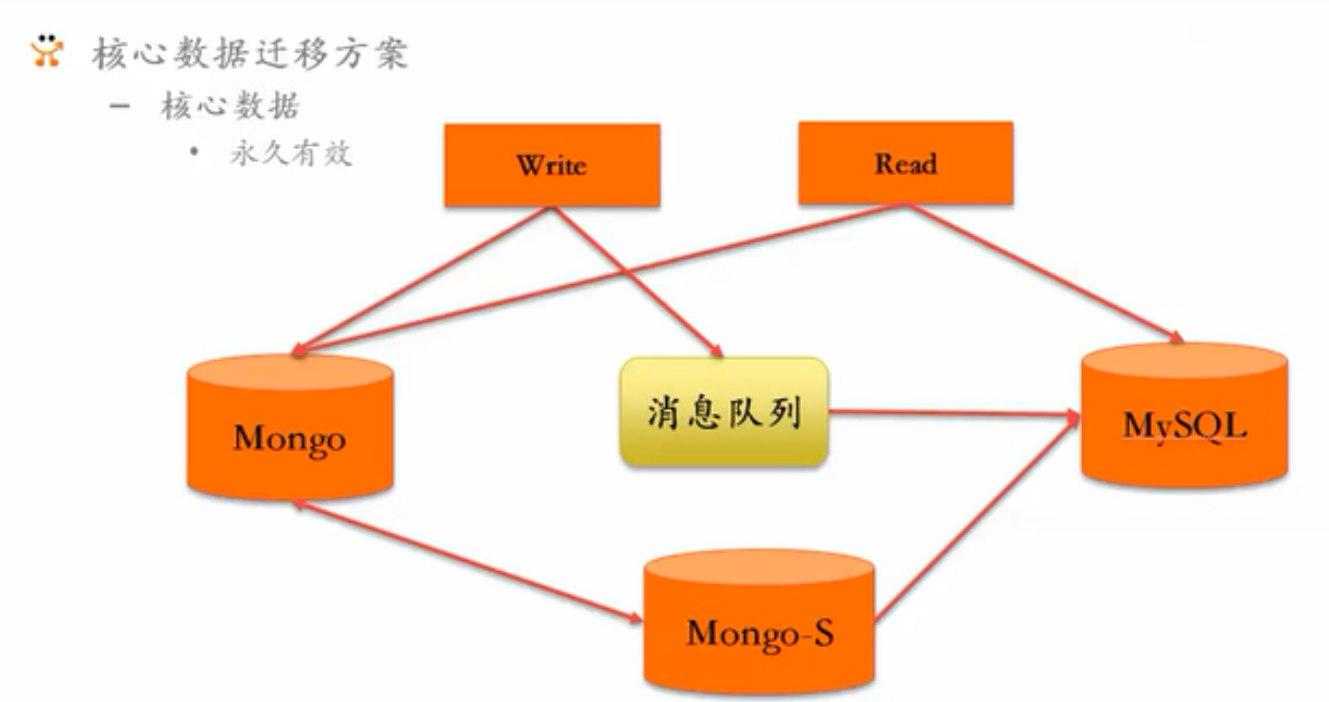
没怎么展开
8.5 高可用架构数据存储层 最佳实践
- feed
表:取模, data:水平拆分 库:分到不同库。 cache集群
- 每个机房都有一套cache,冗余
- 高可用(没必要做高可用?)
- 增加cache集群机器
第九课,分布式缓存
9.0 为什么需要焕春
加速响应速度,延迟小 减少对硬盘的读压力
9.1 使用场景
尽可能缓存
- 静态内容:小文本,视频,css,js
- 较少更改的 : 性别,年龄。
- 读多写少的场景。写一次读十次可以放缓存。写一次读一次的不用放缓存。
- 不适合的场景:
- 频繁更新
- 读少写多的场景
9.2 类型,各自作用
- 本地缓存
- 类目信息(很少变化),进程重启拉进来。减少IO交互。
- 这些要是改的话不用网络交互。节省时间
- 进程内缓存
- 缓存动态数据,
- session相关信息,用户在线隐身离开信息
- 可以定期清除
- 放在远端缓存的话,没办法定期清除。必须拉出来清理再放回去。代价高
- 进程内数据和业务耦合,放在进程内缓存还是合适的。
- 缓存动态数据,
- 分布式缓存
- Memchached(KV分布式缓存)
- 高可用(都有脏数据-一致性问题):解决颁发:时间戳
- 不支持持久化
- redis(KV分布式缓存)
- 5w+吞吐量
- 高可用(SM)
- 持久化 RDB快照,AOF配置刷盘
- 自主研发分布式缓存系统
- redis就可以满足了。redis 好于 memchache
- Memchached(KV分布式缓存)